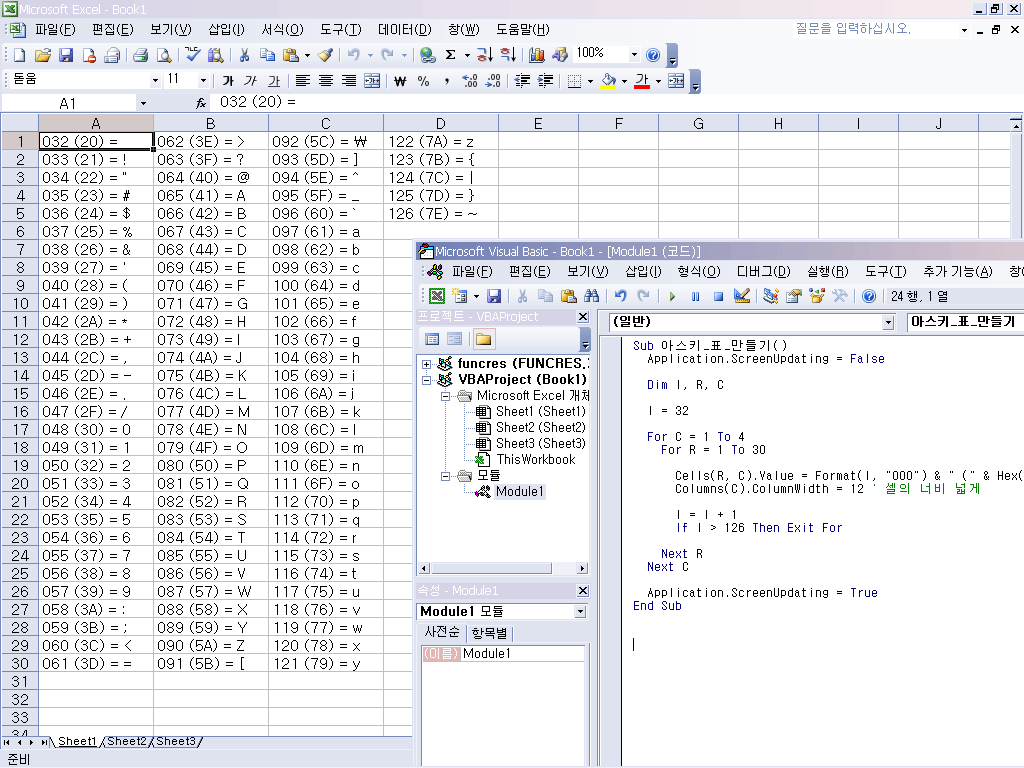
예를 들어 아라비아 숫자 "12345"를, "일만이천삼백사십오"로 변환하는, num2ko.pl 이라는 이름의 펄 프로그램입니다. 무한에 가까운 엄청나게 큰 숫자까지도 셀 수 있습니다.
9가 무려 72개 있는 거대한 숫자를 한글로 읽는 예입니다:
D:\Z>num2ko.pl 99999999999999999999999999999999999999999999999999999999999999999
9999999
구천구백구십구無量大數구천구백구십구不可思議구천구백구십구那由他구천구백구십구阿
僧祇구천구백구십구恒河沙구천구백구십구極구천구백구십구載구천구백구십구正구천구백
구십구澗구천구백구십구溝구천구백구십구양구천구백구십구자구천구백구십구해구천구백
구십구경구천구백구십구조구천구백구십구억구천구백구십구만구천구백구십구
다만, 溝(구)는 9(구)와 혼동되기에, 한자로 표시했고, 溝(구)보다 더 큰 숫자도 한글로 표현하면 가독성이 떨어져서 한자로 나타내었습니다.
물론 현실 세계에서는 "京(경)"을 초과하는 단위, 즉 "해(垓)"부터는 사용되지 않습니다. 그리고 秭(자)라는 글자는 한국어 인코딩으로는 표현되지 않아서, 한글로 "자"라고 쓸 수밖에 없었습니다.
num2ko.pl 은, "Lingua::JA::Number" 라는 CPAN 모듈을, 한국어에 맞게 개조하여 만든 것입니다:
▶▶ 펄/Perl] 아라비아 숫자를, 일본어 숫자 읽기 발음으로 변환, Lingua-JA-Number
아라비아 숫자를 한글로 변환 프로그램
파일명: num2ko.pl
※ 아래 박스 클릭 후, 키보드 화살표 키로 좌우 스크롤 가능함
#!/usr/bin/perl
use strict; use warnings;
&help if $#ARGV == -1;
my %N2K = qw( 1 일 2 이 3 삼 4 사 5 오 6 육 7 칠 8 팔 9 구 10 십 100 백 1000 천 );
my @N2K_BLOCK = ("", "만", "억", "조", "경", "해", "자", "양", "溝", "澗", "正", "載", "極", "恒河沙", "阿僧祇", "那由他", "不可思議", "無量大數");
print &numberToKorean(@ARGV), "\n";
sub numberToKorean {
my $n = join "", @_; # 모든 파라미터 합치기 (공백 넣은 숫자 처리 위해)
my @sign = $n =~ /(^[+-]?)/; # +- 부호 있으면 저장
my @fraction = $n =~ /(\.\d.*$)/; # 소수점 이하 저장
$n =~ s/(\.\d.*$)//; # 소수점 이하 삭제
$n =~ s/\D//g; # 숫자 속의 쉼표 등, 숫자가 아닌 문자는 모두 제거
return "" if $n eq ""; # 숫자가 없으면 빈 문자열 반환
# 0 이면 "영"을 반환
return join("", @sign, "영", @fraction) if $n == 0;
$n =~ s/^0{1,}//g; # 앞쪽에 붙은 0 모두 제거
# 999999999999999999999999999999999999999999999999999999999999999999999999 (구천구백구십구無量大數...) 초과할 때
return join("", @sign, "[ ", length($n), " 자리 숫자 ]", @fraction) if length($n) > 72;
my @result;
$n = reverse $n;
my $bix = 0;
while ($n =~ /(\d{1,4})/g) {
my $b = scalar reverse($1);
my @r = blockof4_to_string($b);
push @r, $N2K_BLOCK[$bix] if ($bix && @r);
unshift @result, @r;
$bix++;
}
return join "", @sign, @result, @fraction;
}
sub blockof4_to_string {
my $n = shift;
return undef if $n > 9999 or $n < 0;
return "" unless $n;
my @result = ();
my @digits = split //, sprintf("%04d", $n);
my @weights = (1000, 100, 10, 1);
for my $i (0..3) {
next unless $digits[$i];
my $v = $digits[$i] * $weights[$i];
push @result, $N2K{$v} || ($N2K{$digits[$i]}, $N2K{$weights[$i]});
}
return @result;
}
sub help {
die <<TEXT;
아라비아 숫자를 한글 발음으로 변환 출력 v1.0
( Original Source: "Lingua::JA::Number" from CPAN )
사용법 : num2ko.pl <number>
사용 예제
..............................................................................
num2ko.pl 12345 num2ko.pl 1111111111111
num2ko.pl 12,345 num2ko.pl 1,111,111,111,111
num2ko.pl 12 345 num2ko.pl 1 111 111 111 111
num2ko.pl 1,2345 num2ko.pl 1,1111,1111,1111
num2ko.pl 1_2345 num2ko.pl 1_1111_1111_1111
일만이천삼백사십오 일조천백십일억천백십일만천백십일
..............................................................................
num2ko.pl 94653744647457537433652113614151363276249302490701430870312503074407
9053
구천사백육십오無量大數삼천칠백사십사不可思議육천사백칠십사那由他오천칠백오십삼
阿僧祇칠천사백삼십삼恒河沙육천오백이십일極천삼백육십일載사천백오십일正삼천육백
삼십이澗칠천육백이십사溝구천삼백이양사천구백칠자백사십삼해팔백칠십경삼천백이십
오조삼백칠억사천사백칠만구천오십삼
..............................................................................
구 간 정 재 극 항하사 아승기 나유타 불가사의 무량대수
溝 澗 正 載 極 恒河沙 阿僧祇 那由他 不可思議 無量大數
TEXT
}
사용법은 쉽습니다. num2ko.pl 뒤에 아라비아 숫자를 적어 주면 됩니다.
실행 결과:
※ 아래 박스 클릭 후, 키보드 화살표 키로 좌우 스크롤 가능함
D:\Z>num2ko.pl 0
영
D:\Z>num2ko.pl 1
일
D:\Z>num2ko.pl 2
이
D:\Z>num2ko.pl 10
십
D:\Z>num2ko.pl 11
십일
D:\Z>num2ko.pl 111
백십일
D:\Z>num2ko.pl 5479341634
오십사억칠천구백삼십사만천육백삼십사
D:\Z>num2ko.pl 999999999999
구천구백구십구억구천구백구십구만구천구백구십구
D:\Z>num2ko.pl 100000000000000
백조
D:\Z>num2ko.pl 1000000000000000000
백경
D:\Z>num2ko.pl 100000000000000000000
일해
D:\Z>num2ko.pl 1000000000000000000000000
일자
D:\Z>num2ko.pl 10000000000000000000000000
십자
D:\Z>num2ko.pl 55555555555555555555555
오백오십오해오천오백오십오경오천오백오십오조오천오백오십오억오천오백오십오만오천
오백오십오
D:\Z>num2ko.pl 5315813753750135731085631086539367311
오澗삼천백오십팔溝천삼백칠십오양삼천칠백오십자천삼백오십칠해삼천백팔경오천육백삼
십일조팔백육십오억삼천구백삼십육만칠천삼백십일
D:\Z>num2ko.pl 10000000000000000000000000000000000000000000000000000000000000000
0000000
천無量大數
D:\Z>num2ko.pl 11111111111111111111111111111111111111111111111111111111111111111
1111111
천백십일無量大數천백십일不可思議천백십일那由他천백십일阿僧祇천백십일恒河沙천백십
일極천백십일載천백십일正천백십일澗천백십일溝천백십일양천백십일자천백십일해천백십
일경천백십일조천백십일억천백십일만천백십일
D:\Z>num2ko.pl 99999999999999999999999999999999999999999999999999999999999999999
9999999
구천구백구십구無量大數구천구백구십구不可思議구천구백구십구那由他구천구백구십구阿
僧祇구천구백구십구恒河沙구천구백구십구極구천구백구십구載구천구백구십구正구천구백
구십구澗구천구백구십구溝구천구백구십구양구천구백구십구자구천구백구십구해구천구백
구십구경구천구백구십구조구천구백구십구억구천구백구십구만구천구백구십구
D:\Z>num2ko.pl 99999999999999999999999999999999999999999999999999999999999999999
99999999999999999999999999999999999999999999999999999999999999999999999999999999
99999999999
[ 156 자리 숫자 ]
윈도우용 펄인
액티브펄(ActivePerl)로 실행한 결과입니다.
숫자 읽기 프로그램을 만들기 위해 한달 가까이 고생을 좀 했습니다. 숫자 읽기라는 것이 "자연어 처리"에 가까운 것이라서 의외로 어려웠습니다.
다행히 CPAN의 "Lingua::JA::Number" 에서 좋은 알고리즘을 발견했습니다.
숫자 한글로 읽기 알고리즘들에는
* 너무 복잡
* 부자연스럽게 읽기 (1010 을 "천십"으로 읽지 않고, "일천일십"으로 읽는 등)
* 버그 (10000 단위 이상을 읽을 수 없는 등)
같은 문제들이 많이 있었습니다. 그렇지만 "Lingua::JA::Number" 알고리즘에서는 그런 문제가 없고 거의 완벽했습니다. 다만 "Lingua::KO::Number" 모듈이 없어서, "Lingua::JA::Number" 를 한글 환경에 맞게 개조를 했습니다.
제가 충분히 디버깅을 했지만 무슨 미묘한 버그가 있을지 모르겠습니다. 실무에 사용할 때에는 충분한 테스트가 필요합니다.
큰 숫자 단위표:
▶▶ 만,억,조,경,해,자,양,구,간,정,재,극,항하사,아승기,나유타,불가사의,무량대수;Large Number
▶▶ Perl/펄] 숫자를 영어 스펠링으로 변환; 영어식으로 읽기; Number to English
tag: perl
Perl | 펄
tag: office
엑셀 Excel | 워드 Word | VBA 매크로 | 오피스